In diesem Beitrag möchte ich einen Klassifikator vorstellen, der auf dem Konzept der k-nächsten Nachbarn basiert. Ich muss zugeben, dass ich mit der Implementierung nicht ganz die gewünschten Ergebnisse erzielt habe. Vielleicht habe ich einfach nicht genug Zeit investiert oder mir fehlen einige Kenntnisse auf diesem Gebiet. Trotzdem möchte ich meine Erfahrungen teilen und hoffe, dass wir gemeinsam darüber diskutieren können.
Die Funktion Euclidean_Metric fungiert als Klassifikator. Sie nutzt eine vorhandene Vektorbasis, die entweder die Trades oder Marktsituationen beschreibt. Anhand dieser Funktion wird ermittelt, ob ein Eingangsvektor zu einer der Gruppen in der Basis gehört. Die Vektoren werden vom Nutzer in Gruppen eingeteilt: Ein Trade, der mit einem positiven Ergebnis endet, gehört zur Klasse 1, während negative Ergebnisse Klasse 0 zugeordnet werden. Die Suche nach den nächsten Nachbarn eines mehrdimensionalen Vektors erfolgt über die euklidische Distanz. Anschließend wird berechnet, wie viele dieser k-Vektoren zur Klasse 1 gehören. Diese Zahl wird dann durch die Gesamtanzahl der Nachbarn (also durch k) geteilt, um die Wahrscheinlichkeit zu ermitteln, dass der gegebene Vektor zur Klasse 1 gehört.
Allerdings kann man der Klassifikation nicht immer vollkommen vertrauen, insbesondere wenn die ausgewählten Koordinaten der Vektoren „schlecht“ gewählt sind (d.h. über 0,5 oder unter 0,5). Daher wurde ein zusätzlicher Schwellenwert eingeführt: Wenn die Wahrscheinlichkeit, dass ein zukünftiger Trade profitabel ist, höher als 0,7 ist, dann sollte man in den Markt eintreten. Die Verhältnisse der gleitenden Durchschnitte wurden als Maße (Koordinaten) der Vektoren herangezogen, unter der Annahme, dass diese Verhältnisse statisch sind und die Klassifizierung der Vektoren (Trades) einmal durchgeführt werden kann, um sie auch in den Vorwärts-Tests zu verwenden. Doch so einfach ist das nicht :) Warum ausgerechnet k-nächste Nachbarn? Weil der erste nächste Nachbar möglicherweise ein abnormaler Ausreißer ist, der ohne Berücksichtigung eines Clusters von entgegengesetzten Vektoren in der Nähe für die Klassifikation ausgewählt wird. Eine detaillierte Beschreibung findet sich in S. Haykin „Neurale Netzwerke: Eine umfassende Grundlage“ (Lernmethoden).
Der Klassifikator hat zwei Hauptprobleme:
- 1) Die statischen Daten, die die Marktsituationen (oder zukünftige Trades) beschreiben, mit der erforderlichen Genauigkeit oder dem notwendigen Niveau der korrekten Klassifizierung zu finden.
- 2) Das große Volumen an mathematischen Operationen, was zur Folge hat, dass die Berechnung eine Weile dauert… (übrigens etwas weniger als PNN).
Zusammengefasst sind die Probleme ähnlich wie bei herkömmlichen Trading-Systemen. Der Vorteil ist, dass der Klassifikator Bedingungen formalisiert, die der Trader nicht sieht, aber intuitiv spürt, dass bestimmte Werte des Indikators Einfluss darauf haben, ob ein Trade eröffnet werden sollte.
Nun zur konkreten Implementierung.
Base - true: eine Datei mit der Vektorbasis schreiben; false: Handel mit Klassifizierung…
buy_threshold = 0,6: Schwellenwert für alle Buy-Positionen.
sell_threshold = 0,6: ebenso für Sell-Positionen.
inverse_position_open? = true; Dies ist ein interessanter Punkt. Wenn die Wahrscheinlichkeit eines profitablen Trades sehr gering ist, warum dann nicht mit einer inversen Position in den Markt eintreten? Dieses Flag ermöglicht solche Positionen.
inverse_buy_threshold = 0,3: Schwellenwert, bei dem die Wahrscheinlichkeit einer profitablen Buy-Position geringer ist, dann eine Sell-Order eröffnen.
inverse_sell_threshold = 0,3; ebenso…
fast = 12: Parameter von MACD.
slow = 34;
tp = 40; Take Profit.
sl = 30; Stop Loss.
close_orders = false; Flag, um das Schließen nur bei einem gegenteiligen Signal zu ermöglichen, wenn die Order im Gewinn ist…
Verwendung: Zuerst Flag Base - true setzen, sl = tp setzen und einmal auf historische Daten anwenden (einmal!), die Vektordatei wird geschrieben. Beim nächsten Mal Base - false setzen und es wird empfohlen, die Schwellenwerte zu optimieren. Ich wähle sie basierend auf dem ersten Bericht (ohne Klassifizierung). Wenn die Erfolgswahrscheinlichkeit = 0,5 ist, dann sind die Schwellenwerte 0,6 und 0,4 (um die Position zu invertieren).
Noch einmal, dies ist nur ein Beispiel; der Klassifikator kann auf andere Trading-Systeme in ähnlicher Weise angewendet werden, mit anderen Eingangsdaten.
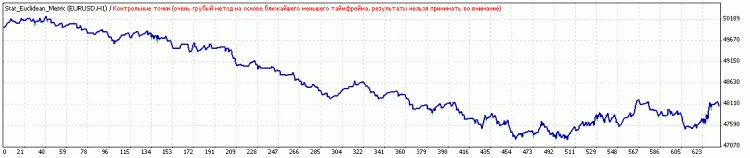
Vor der Klassifikation:
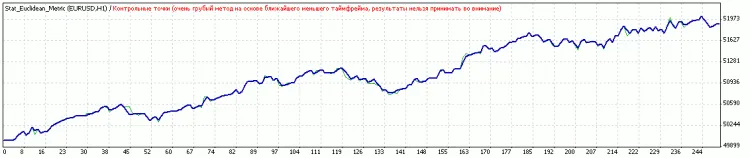
Nach der Optimierung der Schwellenwerte.
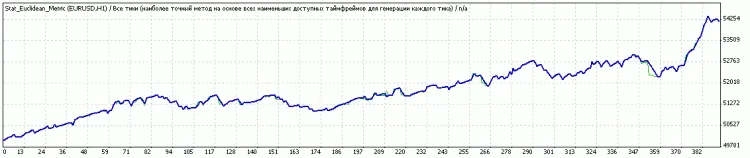
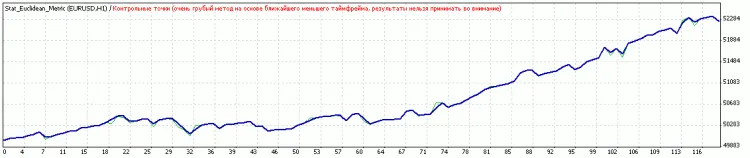




Kommentar 0