안녕하세요, 트레이더 여러분! 오늘은 k-최근접 이웃(k-NN) 알고리즘을 활용한 분류기에 대해 이야기해볼까 해요. 이 방법은 메모리를 기반으로 한 분류기로, 여러분의 트레이딩 전략에 활용될 수 있을지에 대해 논의해 보려 합니다.
우선, Euclidean_Metric 함수는 분류기 역할을 합니다. 이 함수는 거래 또는 시장 상황을 설명하는 벡터를 활용하여, 입력 벡터가 데이터베이스의 어떤 그룹에 속하는지를 결정합니다. 예를 들어, 거래가 이익으로 종료되면 클래스 1, 손실로 종료되면 클래스 0으로 분류하죠. 다차원 벡터의 최근접 이웃을 찾는 것은 유클리드 거리를 통해 이루어집니다. 이렇게 계산된 클래스 1에 속하는 k-벡터의 수를 세고, 이를 총 이웃 수(k)로 나누어 주어진 벡터가 클래스 1에 속할 확률을 계산합니다.
그러나 벡터의 좌표가 부적절하게 선택된 경우, 이 분류는 신뢰할 수 없을 수 있습니다. 그래서 추가적인 임계값을 설정했는데요, 예를 들어 미래 거래의 수익 가능성이 0.7 이상일 경우에만 시장에 진입하는 방식입니다. 이동 평균의 비율이 벡터의 좌표로 사용되며, 한 번 분류한 벡터는 향후 테스트에서도 활용할 수 있다고 가정합니다. 하지만 이 과정이 생각만큼 간단하지는 않아요.
분류기의 두 가지 문제점
- 1) 시장 상황(혹은 미래 거래)을 설명하는 정적 데이터를 찾기가 어렵습니다.
- 2) 수학적 연산량이 많아 계산 시간이 오래 걸립니다.
간단히 말해, 이 문제들은 기존의 트레이딩 시스템과 거의 비슷합니다. 하지만 이 분류기는 트레이더가 직관적으로 알아차리지 못하는 조건을 형식화할 수 있는 장점이 있습니다.
구현 방법
이제 구체적인 구현 방법에 대해 알아보겠습니다.
- Base - true일 경우 벡터 데이터를 파일로 저장하고, false일 경우 분류를 통해 거래합니다.
- buy_threshold = 0.6: 모든 매수 포지션의 기준입니다.
- sell_threshold = 0.6: 모든 매도 포지션의 기준입니다.
- inverse_position_open = true: 수익 가능성이 매우 낮을 경우 반대 포지션으로 진입할 수 있습니다.
- invers_buy_threshold = 0.3: 수익 가능성이 낮을 경우 매도 거래를 개시합니다.
- fast = 12, slow = 34: MACD의 파라미터입니다.
- tp = 40: 테이크 프로핏.
- sl = 30: 스톱로스.
- close_orders = false: 수익이 있는 경우에만 반대 신호로 주문을 종료합니다.
사용 방법으로는 우선 Base를 true로 설정하고, sl을 tp와 동일하게 맞춘 후 역사 데이터를 실행합니다. 벡터 파일이 작성된 후에는 Base를 false로 설정하고 임계값을 최적화하는 것이 좋습니다. 성공 확률이 0.5라면 임계값은 0.6과 0.4로 설정합니다.
다시 말해, 이 분류기는 다른 트레이딩 시스템에도 동일한 방식으로 적용할 수 있습니다.
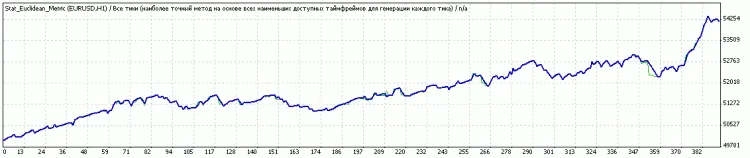
분류 전후 결과
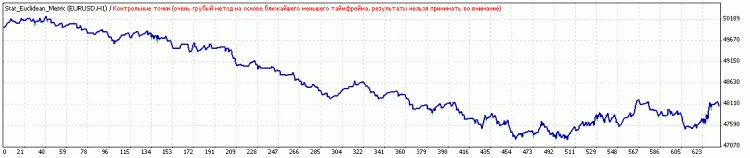
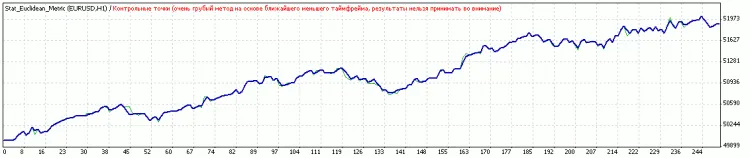
임계값 최적화 후 결과
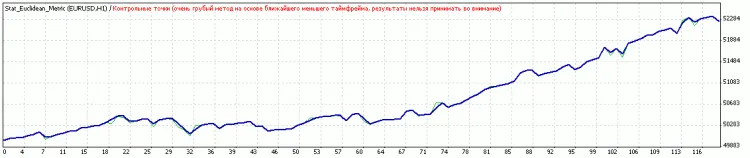




댓글 0